# Java Web
对《深入分析Java Web技术内幕》一书中以前不懂的知识点进行记录。
# 常见的HTTP请求头,响应头,状态码信息都有哪些?
# 请求头
| 请求头 | 说明 |
|---|---|
| Accept-Charset | 用于指定客户端接受的字符集。 |
| Accept-Encoding | 用于指定可接受的内容编码,如Accept-Encoding:gzip.deflate。 |
| Accept-Language | 用于指定一种自然语言,如Accept-Language:zh-cn。 |
| Host | 用于指定被请求资源的Internet主机和端口号,如Host:www.taobao.comHTTP协议Host请求头的作用 (opens new window)。 |
| User-Agent | 客户端把它的操作系统,浏览器和其他属性告诉服务器。 |
| Connection | 是否保持连接,如Connection:Keep-Alive。 |
# 响应头
| 响应头 | 说明 |
|---|---|
| Server | 使用的WEB服务器名称,如Server:Nginx。 |
| Content-Type | 用来指定发送给接收者的实体正文的媒体类型,如Content-Type:text/html;charset=GBK。 |
| Content-Encoding | 与请求头中Accept-Encoding对应,告诉浏览器服务端采用的是什么压缩编码。 |
| Content-Language | 描述了资源所用的自然语言,与Accept-Language对应。 |
| Content-Length | 指定实体正文的长度,用以字节方式存储的十进制数字表示。 |
| Keep-Alive | 保持连接的时间,如Keep-Alive:timeout=5,max=120 表示5毫秒后超时,还能请求120次。 |
# 状态码
| 状态码 | 说明 |
|---|---|
| 500 | 服务器发生不可预期的错误。 |
| 404 | 404 Not Found,请求的资源不存在。 |
| 403 | 403 Forbidden,禁止访问。通常应用于身份验证通过但权限不足的情况。客户端已验证身份,但由于权限不足,服务器拒绝了请求。 |
| 401 | 401 Unauthorized(未授权)。通常表示请求需要身份验证,但客户端未提供有效的凭据(如未提供令牌或用户名密码)。 |
| 400 | 400 Bad Request (客户端请求存在语法错误,服务端不能解析)。如请求头不符合HTTP格式规范,用了服务器不支持的请求方法等原因。解析HTTP错误码400 Bad Request及其常见原因与解决方法 (opens new window) |
| 304 | 一般由服务器返回,告知浏览器当前请求的资源是最新的,浏览器直接使用缓存即可。 |
| 302 | 临时重定向。HTTP状态码301和302,你都了解有哪些用途吗 (opens new window) |
| 301 | 永久重定向。 |
| 200 | 客户端请求成功。 |
# 浏览器缓存机制
默认情况下,浏览器会对请求的静态资源进行缓存,此外,如果后端服务部署了缓存服务器,后端服务器同样会对静态资源进行缓存,如果需要取消这个缓存,可按约定的规范,在请求的请求头中添加Pragma:no-cache属性以及Cache-Control:no-cache参数来实现。添加了这两个参数的请求,浏览器及后端的静态资源缓存服务器均不会使用缓存。以下是Cache-Control的可选值:
| 可选值 | 说明 |
|---|---|
| Public | 在响应头设置,所有内容都将被缓存。 |
| Private | 在响应头设置,所有内容只缓存到私有缓存中。 |
| no-cache | 不使用缓存,在请求头或响应头设置均可对该请求生效。 |
| no-store | 在响应头设置,所有内容都不会被缓存。 |
| must-revalidation/proxy-revalidation | 在请求头设置,浏览器对服务端的静态资源缓存服务器的缓存要求,如果缓存的内容失效,请求必须发送到服务器/代理进行重新验证。 |
| max-age=xxx | 在响应头设置,缓存的内容将在XXX秒后失效,这个选项只在HTTP1.1可用。 |
# DNS域名解析过程
DNS域名解析过程,主要有浏览器缓存,解析hosts文件,LDNS(Local DNS Server)服务器解析,Root Server根域名服务器,gTLD主域名服务器解析,Name Server服务器解析过程组成。
# 1.浏览器缓存
当一个使用域名的URL在浏览器中请求时,浏览器会首先在缓存中查找域名及IP映射关系,如能找到,即可将域名解析为IP地址,如缓存无数据,执行步骤2.解析hosts文件。
# 2.hosts文件
在Win环境下,hosts文件的地址在C:\Windows\System32\drivers\etc\hosts,在Linux环境下,hosts文件的地址在/etc/hosts,在hosts文件中,我们可以配置域名及ip地址的映射关系(一般配置该文件仅用于测试服务在真实的域名环境的访问效果)。如hosts文件中无法解析域名,执行步骤3.LDNS解析。
# 3.LDNS解析
在Win环境下我们可以通过ipconfig /all指令来查找本机的域名解析服务器,即LDNS的ip地址。
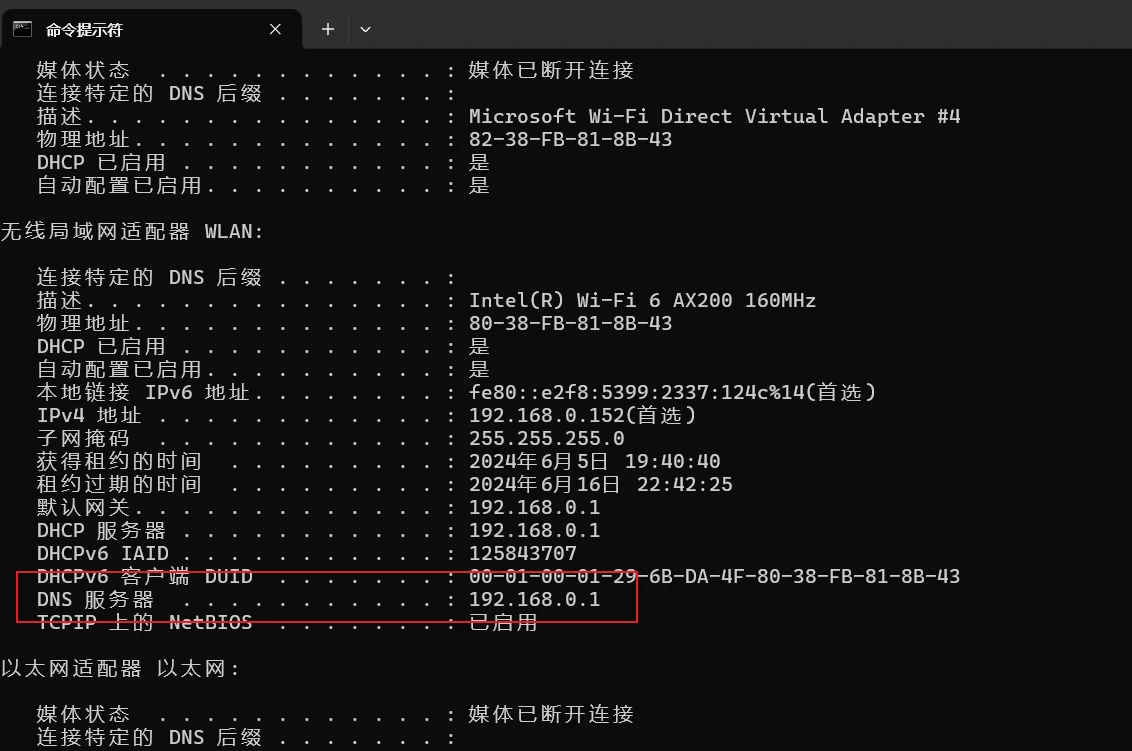
在Linux环境下我们可以通过cat /etc/resolv.conf指令来查找本机的域名解析服务器。
大约80%的域名解析都由LDNS服务器完成,所以LDNS主要承担了域名的解析工作。如LDNS无法命中,就直接到Root Server根域名服务器解析请求。
# 4.根域名服务器解析
根域名服务器返回本地域名服务器一个所查询域的主域名服务器(gTLD Server)地址,gTLD是国际顶级域名服务器,如.com,.cn,.org等,全球只有13台。
# 5.请求gTLD服务器
本地域名服务器请求gTLD服务器,gTLD服务器会查找并返回域名所对应的Name Server域名服务器的地址,这个Name Server通常是域名所在的域名服务器的地址(如我的域名的Name Server是山东烟台帝思普)。
# 6.请求Name Server
本地域名服务器请求Name Server,获取域名解析后的ip,保存在本地域名服务器,然后返回给用户浏览器。域名解析动作完成。
补充资料:如何查询域名解析结果?
在Windows及Linux下,我们均可使用nslookup指令来查询域名的解析结果。
在Linux环境下,我们还可以使用dig www.kieoo.com +trace来跟踪域名解析的完整过程。
补充资料:如何清除当前主机下缓存的域名?
在Win环境下,可以使用ipconfig /flushdns指令来清理dns缓存。
在Linux环境下,可以使用/etc/init.d/nscd restart来清理dns缓存。
补充资料:几种域名解析方式
域名解析记录主要分为A记录,MX记录,CNAME记录,NS记录,TXT记录。
1.A记录:Address地址记录,用于指定域名对应的IP地址,如将www.kieoo.com指定为43.139.88.150。A记录可以将多个域名解析为同一个IP地址,但是不能将一个域名解析到多个IP地址。
2.MX记录,表示Mail Exchange,如果将MX记录设置为43.139.88.150,DNS会自动将邮件xxxx@kieoo.com解析到43.139.88.150上的邮件服务器。
3.CNAME,表示别名解析,即为一个域名设置别名(别名为另一个域名),这样一个域名就会被解析为另一个域名,最终会解析到A记录,即某一个域名的IP地址。
4.NS记录,将域名解析工作交给特定的服务器,而不是直接将域名解析为IP地址。
5.TXT记录,为某个主机名或域名设置说明,意义不大(也可以在其中设置电话号码用于联系)。
# CDN工作过程
CDN也就是内容分发网络(Content Delivery Network)主要用来分发css,js,图片,静态页面等数据。用户从主站服务器上请求动态内容后,再从CDN上下载静态资源,从而加速网页数据内容的下载速度。
用户请求某个静态资源(如css文件),这个资源的域名是cdn.kieoo.com,首先浏览器会向Local DNS服务器发起请求,然后会走到域名的Name Server去解析,Name Server上一般该域名都会配置NS记录,最终域名会回到注册服务器(43.139.88.150)上面的DNS解析服务去解析(如我的域名kieoo.com在烟台帝思普配置了NS记录)。这时我的域名解析服务器就会把当前域名CNAME解析到另外一个域名,而这个域名最终指向的是CDN全局中的DNS负载均衡器(GTM),GTM会负载一个最近的节点的ip地址给用户,即cdn.kieoo.com这个域名会被解析为一个对当前用户来说网络环境最好的静态资源服务器的ip地址。
# DCDN动态加速
CND加速只针对静态资源(css,js,html)等文件进行加速,DCDN则可以对静态资源以及动态资源(如业务接口)进行加速,此外DCDN还具备算法自动寻路的功能,可以自动找到就近的节点为用户提供服务。
# 短链域名解析原理
参考短url域名是怎么设计的 (opens new window),大体思路就是自己买一个比较短的域名,在域名所在的ip的服务器上部署nginx+openresty+redis,对原始地址做一个Hash运算,运算结果作为key,原始地址作为value存在redis中,当用户请求短域名/hash的url的时候,nginx解析请求,读取redis,获取原始地址,填充到响应头中,同时修改响应头的Http状态码为302(临时重定向),依赖浏览器的能力做临时重定向跳转即可。
# 应用程序访问文件的几种方式?
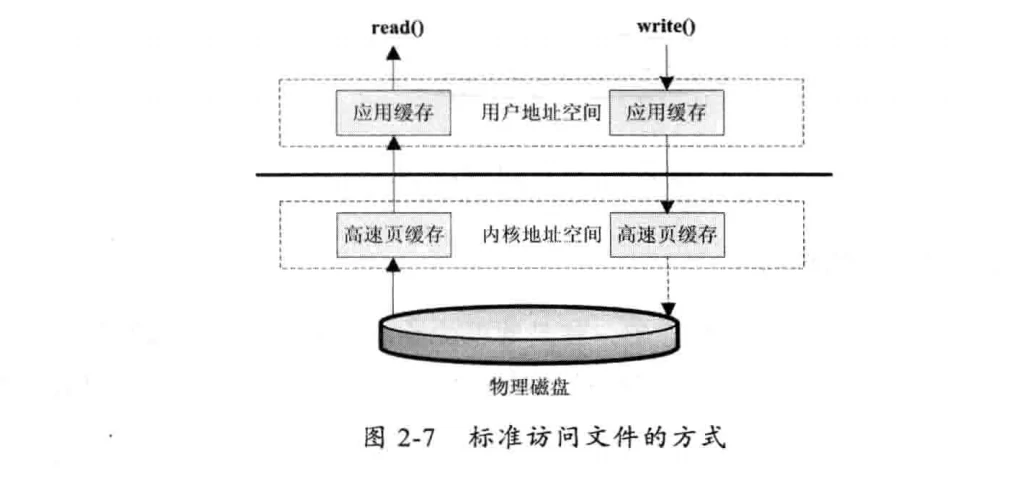
# 标准IO访问文件的方式
标准IO也称为缓存IO,标准访问文件的方式就是应用程序调用read()接口的时候,操作系统会检查内核中的高速缓存中是否有需要的数据,如果缓存中有,那么就直接从缓存中获取。如果缓存中没有,则从磁盘中读取,然后缓存到高速缓存中。
写入的方式是,用户的应用程序调用write()接口将数据从用户地址空间复制到内核地址空间的高速缓存中。这时对用户程序来说写入操作就已经完成了,至于什么时候写入磁盘则由操作系统决定,除非显示调用sync同步命令。
# 直接I/O的方式
所谓的直接I/O的方式就是应用程序直接访问磁盘数据,而不经过操作系统内核数据缓冲区,这样做的目的就是可以减少一次从内核缓冲区到用户程序缓存的数据复制。这种访问文件的方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中。如在数据库管理系统中,系统明确的知道应该缓存哪些数据,应该失效哪些数据。还可以对一些热点数据做预加载,提前将热点数据加载进内存,可以加速数据的访问效率。在这些情况下,如果由操作系统进行缓存,则很难做到,因为操作系统并不知道哪些是热点数据。哪些数据可能只会访问一次就不会再访问,操作系统只是简单的缓存最近一次从磁盘读取的数据。
直接I/O也有负面影响,如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓慢,通常直接I/O与异步IO结合使用,会获得比较好的性能。

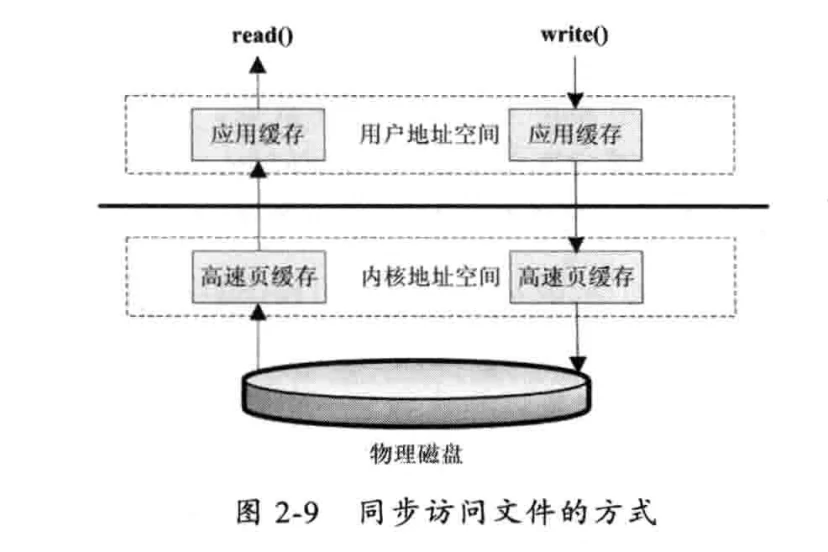
# 同步访问文件的方式
同步访问文件的方式比较好理解,就是数据的读取和写入都是同步操作的,它与标准访问文件的方式不同的是,只有当数据被成功写入磁盘时才会返回给应用程序成功的标志。
这种访问文件的方式性能非常差,只有在一些对数据安全要求非常高的场景中才会使用,而且这种方式通常所需的硬件都是定制的。
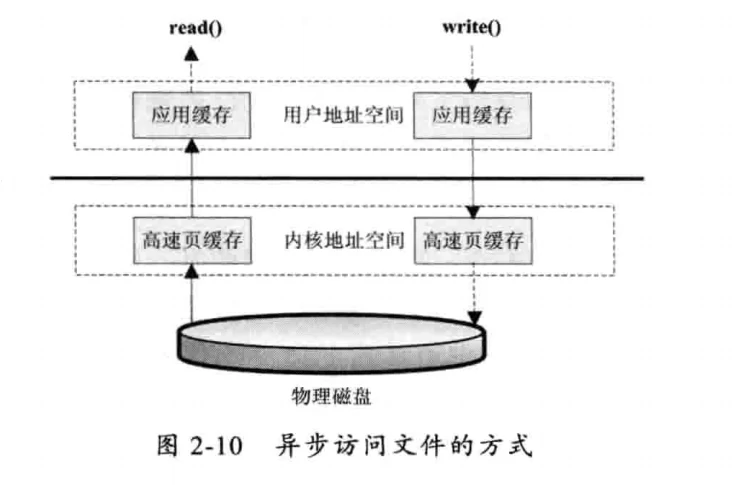
# 异步访问文件的方式
异步访问文件的方式就是当访问数据的线程发出请求之后,线程会接着去处理其他事情,而不是阻塞等待,当请求的数据返回后继续处理下面的操作。这种访问文件的方式可以明显地提高应用程序的效率,但是不会改变访问文件的效率。
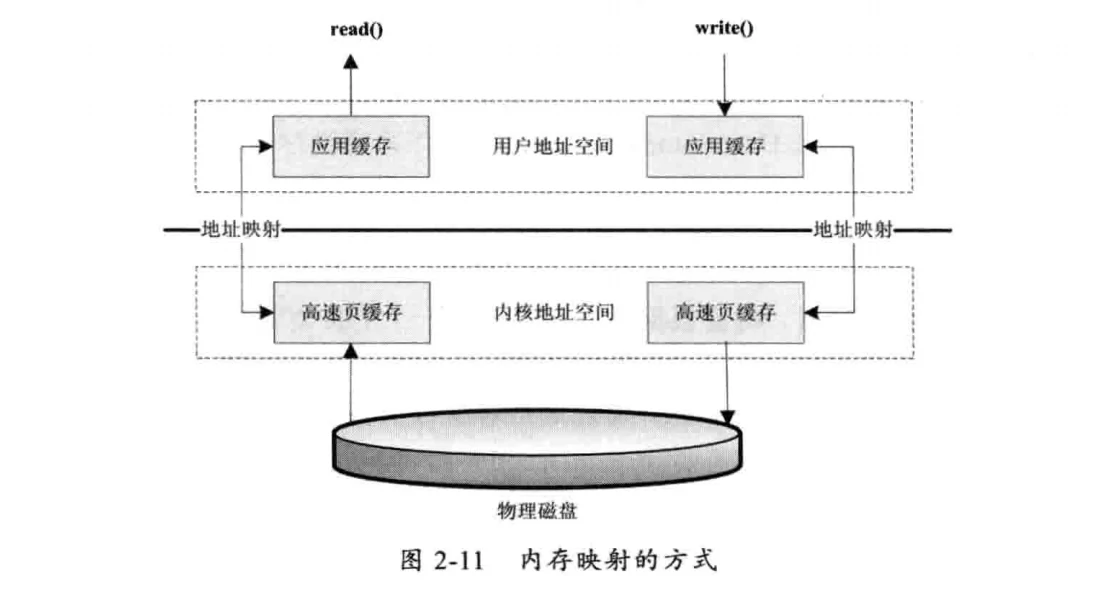
# 内存映射的方式
内存映射的方式是指操作系统将内存的一部分区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据从内核空间缓存到用户空间缓存的数据复制操作,因为这两个空间的数据是共享的。
# Java NIO与零拷贝
java在NIO中对IO的性能做了一些优化处理,如FileChannel.transferTo(),FileChannel.transferFrom()与传统的访问文件方式相比,可以减少数据从内核到用户空间的复制,数据直接在内核空间中移动,在Linux中使用sendfile系统调用。
FileChannel.map()将文件按照大小映射为内存区域,当程序访问这个内存区域时直接操作这个文件数据。这种方式省去了数据从内核空间向用户空间复制的损耗。这种方式适合对大文件的只读操作,如大文件的MD5校验。
# NIO以及buff的工作方式
待补充
# SOCKERT及端口号占用问题
如何在 Socket 中显式为客户端分配端口号? (opens new window)
# BIO,NIO,AIO服务端以及客户端的区别?
客户端(浏览器)与服务端(Server)都可以使用BIO,NIO,AIO进行交互,也就是说,即使服务端是BIO,客户端依然可以是AIO。按现在的情况,浏览器大概是使用NIO Client,服务端使用NIO Server。像nginx,直接使用epoll模型,性能更快且线程数更多(支持更高的并发)。
# 阻塞IO,IO多路复用的区别?
阻塞IO(BIO)是指对IO的操作read()和write()方法会阻塞线程,IO多路复用(select,pull,epoll)对应NIO
# Web的本质是什么?
远程文件读写,每一个Http链接在Linux操作系统里都对应一个文件
# CPU的工作原理
当有任务的时候,CPU就会执行任务,没有任务的时候,CPU就会执行一段“循环代码”,进入休眠状态。当有新的任务的时候,会唤醒CPU,CPU会接着执行新任务。只要通电,CPU就一直在处理任务,这点与我们的大脑类似。
# 操作系统的工作原理
操作系统的代码实际上是由while循环以及信号来控制,当没有信号的时候,代码就在while循环中执行,当有信号的时候(如按下键盘,移动鼠标),就会触发信号中断,然后执行具体的代码逻辑。
# BIO与Socket通信
当使用BIO进行Socket通信的时候,对每一个Socket链接,服务端与客户端都会同时创建一个文件以及启动一个线程,数据传输的过程就对应文件的读写过程。当文件可读/可写的时候,操作系统会发出文件读写信号,当线程执行文件read(),write()方法的时候没有收到读写信号,当前线程就会阻塞。说白了BIO的出现很早,类比到我们开发代码就是代码能完成基本的业务逻辑。这个阶段,文件IO读写阻塞线程也不会成为什么“瓶颈”。
# IO多路复用与NIO与Socket通信
随着访问量增加,IO阻塞线程成为了瓶颈,这时,操作系统也提供了新的优化方案,也就是IO多路复用(select,poll,epoll),在文件不可读写的时候,当前线程并不会阻塞,操作系统提供了底层支持后,Java1.4也提供了新的IO代码,也就是NIO,对应Selector,Channel,Buffer等几个关键类。至此,Java Web服务器(如Tomcat)的底层Socket就被优化成了NIO方案,服务器的性能也有所提高。
# BIO,NIO服务端与客户端
基于BIO,NIO我们可以同时实现服务端以及客户端,服务端与客户端通信是基于Socket,而不是基于IO读写,因此,即使我们的服务端是基于BIO实现,客户端(如浏览器)是基于NIO实现的,他们依然可以正常通信。
# TCP网络参数调优
| 网络参数 | 说明 |
|---|---|
| echo "1024 65535" > /proc/sys/net/ipv4/ip_local_port_range | 设置向外连接可用端口范围。 |
| echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse | 设置time_wait连接重用。 |
| echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle | 设置快速回收time_wait连接。 |
| echo 180000 > /proc/sys/net/ipv4/tcp_max_tw_buckets | 设置最大time_wait连接长度。 |
| echo 0 > /proc/sys/net/ipv4/tcp_timestamps | 表示是否启用以一种比超时重发更精准的方法来启用对RTT的计算。 |
| echo 1 > /proc/sys/net/ipv4/tcp_window_scaling | 设置TCP/IP会话的滑动窗口大小是否可变。 |
| echo 20000 > /proc/sys/net/ipv4/tcp_max_syn_backlog | 设置最大等待处于客户端还没有应答回来的连接数。 |
| echo 2000000 > /proc/sys/fs/file-max | 设置最大打开文件数。 |
需要注意,以上设置都是临时性的,重启linux主机后相关配置就会丢失,另外Linux还提供了一些工具用于查看当前的TCP统计信息,如下:
- cat /proc/net/netstat: 查看TCP的统计信息。
- cat /proc/net/snmp: 查看当前系统的链接情况。
- netstat -s: 查看网络的统计信息。
# 几种常见的编码格式
# ASCII码
ASCII码占用1个byte,总共有128个字符,用1个字节的低7位表示,0~31是用来控制字符如换行、回车、删除等,32到126是打印字符,可以通过键盘输入并且能够显示出来。
# ISO-8859-1
ASCII的128字符显然是不够用的,于是ISO组织在ASCII的基础上又定制了新标准来扩展ASCII,这个新标准就是ISO-8859-1,ISO-8859-1同样占用1个byte,它可以表示256个字符。
# GB2312
GB2312的全称是《信息技术中文编码字符集》,它是双字节编码,总的编码范围是A1~F7,其中A1~A9是符号区,总共包含682个符号,B0~F7是汉字区,包含6763个汉字。
# GBK
GBK全称是《汉字内码扩展规范》,它的出现是为了扩展GB2312,并加了更多的汉字。它能表示21003个汉字,它的编码和GB2312是兼容的,也就是用GB2312编码的汉字可以用GBK来解码,并且不会出现乱码。
# UTF-16
说到UTF必须提到Unicode,ISO试图创建一个全新的超语言字典,世界上所有的语言都可以通过这个字典来互相翻译。UTF-16具体定义了Unicode字符在计算机中的存取方法。UTF-16用两个字节来表示Unicode的转化格式,它采用超长的表示方法,即不论什么字符都用两个字节来表示。
两个字节是16个bit,所以叫UTF-16。UTF-16表示字符非常方便,每两个字节表示一个字符,这就大大简化了字符串操作,这也是Java以UTF-16作为内存的字符存储格式的一个很重要的原因。
# UTF-8
UTF-16采用统一两个字节来表示一个字符,虽然在表示上非常简单,方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要用两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的情况下,这样会增大网络传输的流量,而且也没有必要。而UTF-8采用了一种变长技术,每个编码区域有不同的编码长度。不同类型的字符由1~6个字节组成。
UTF-8有如下的编码规则:
如果是1个字节,最高位(第8位)为0,则表示这是一个ASCII字符,可见ASCII编码已经是UTF-8了。
如果是1个字节,以11开头,则连续的1的个数暗示这个字符的字节数,例如110xxxxx代表它是双字节UTF-8字符的首字节。
如果是1个字节,以10开始,表示它不是首字节,则需要向前查找才能得到当前字符的首字节。
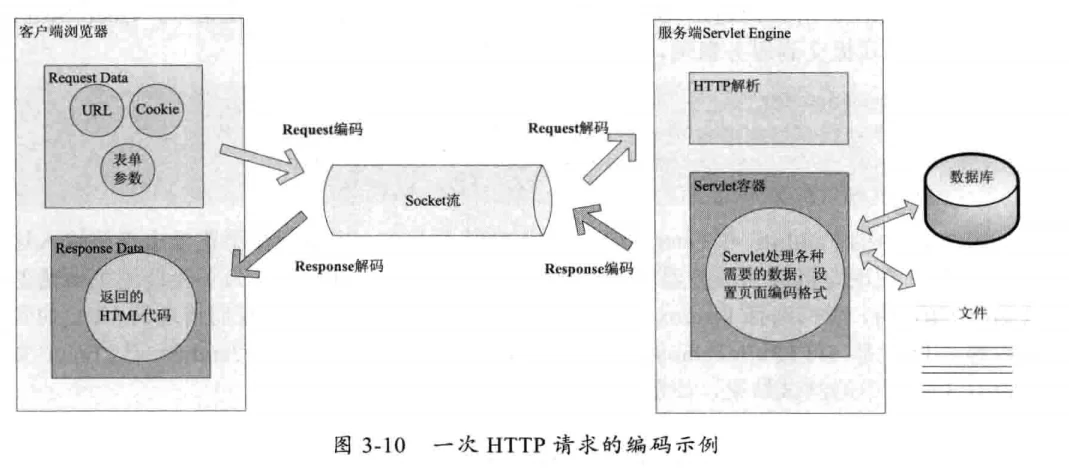
# HTTP请求中哪些地方涉及编解码
在一个HTTP请求中,请求URL,请求Header,POST表单参数,后端服务数据库中数据,文件等都涉及编码及解码操作。
# URL的编解码
用户提交一个URL,这个URL中可能包含中文,因此需要编码。以下是一个URL的构造:
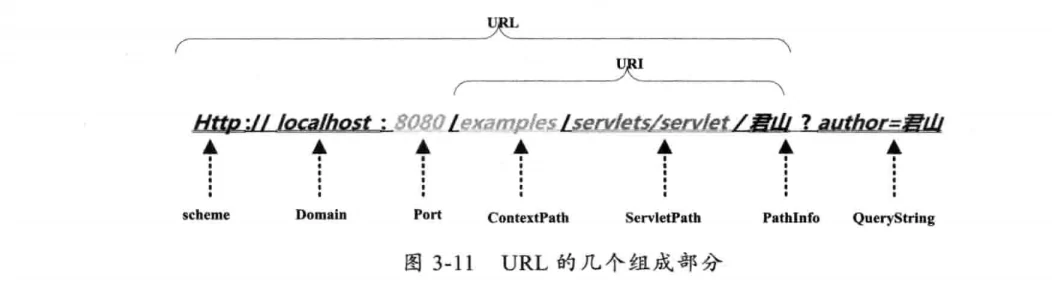
浏览器(客户端)对URL中PathInfo使用UTF-8格式编码,对QueryString用GBK进行编码,浏览器编码URL是将非ASCII字符按照某种编码格式编码成16进制数字后再将每个16进制表示的字节前加上“%”。
服务端(如tomcat)会对PathInfo编码结果进行解码,Tomcat会读取
服务端(如tomcat)会对QueryString编码结果进行解码,解码字符集默认使用ISO-8859-1,如果修改了
# HTTP Header的编解码
Header的编解码只能使用ISO-8859-1,且不支持其他编码格式,所以如果你设置的Header中有非ASCII字符,解码中肯定会出现乱码。
我们在添加Header时也是一样,不要在Header中传递非ASCII字符,如果一定要传递,可以先将这些字符用URLEncoder编码,再添加到Header中,这样在从浏览器到服务端的传递就不会丢失信息了,我们要访问这些项时再按照相应的字符集解码即可。
# POST请求Body部分的编解码
POST表单中的内容是通过HTTP的BODY传递到服务端的,当我们在页面上点击提交按钮时浏览器首先根据ContentType的Charset编码格式对在表单中填入的参数进行编码,然后提交到服务端,服务端同样使用ContentType中的字符集进行解码。
# HTTP ResponseBody的编解码
当用户请求的资源已经成功获取后,这些内容将通过Response返回给客户端浏览器。这个过程要先经过编码,再到浏览器中解码,编解码字符集可以通过response.setCharacterEncoding来设置,它将覆盖request.getCharacterEncoding的值,并且通过Header的Content-Type来返回客户端。浏览器接收到返回的Socket流时将通过Content-Type的charset来解码。如果返回的HTTP Header中Content-Type没有设置charset,那么浏览器将根据HTML的<meta HTTP-equiv="Content-Type" content="text/html;charset=GBK"/>标签中的charset来解码。如果也没有定义,那么浏览器将使用默认的编码来解码。
# JS文件中的编解码
# 外部引入的js文件
我们使用<script src="statics/js/script.js" charset="GBK"/>引入外部js文件的时候需要指定编码格式,如不指定,浏览器会默认使用引入这个js的当前页面的默认字符集解析js文件,如格式不一致,就会出现乱码问题。
# JS的URL编码
通过JS发起异步请求时调用的URL的默认编码也受浏览器影响,针对这种情况,提前使用如下encodeURI(),decodeURI()两个方法对URL进行编解码即可。
- encodeURI() 将这个URL中的特殊字符进行编码,可以使用decodeURI()函数进行解码。
# Java与JS的编解码问题
在前端用encodeURI()编码的URL可以在后端用Java中的URLDecode类解码,同理在后端用URLEncode()编码的URL也可以通过js中的decodeURI()解码。
# 其他编解码场景
除了URL和参数编码问题,在服务端还有很多地方可能涉及编码,如可能需要读取XML,JSP,从数据库读取数据等。
XML文件可以通过设置头来指定编码格式:
<?xml version="1.0" encoding="UTF-8"?>
# 常见编解码问题分析
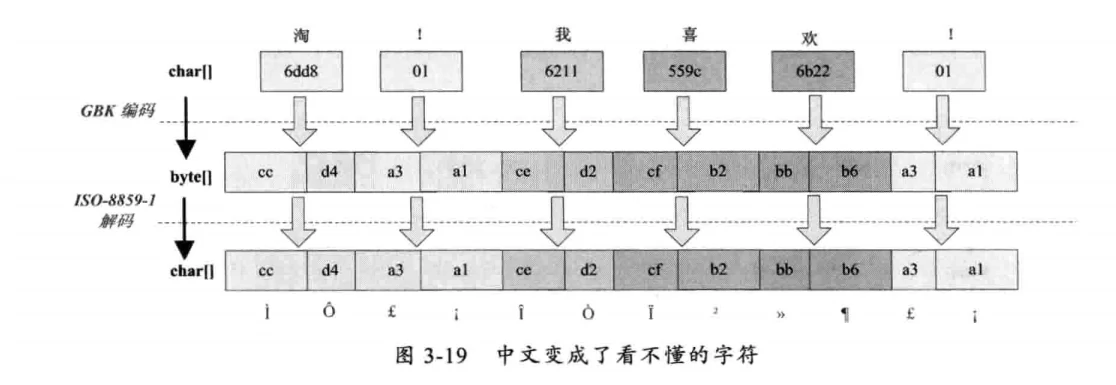
# 中文变成了看不懂的字符
字符串在解码时所使用的字符集与编码时使用的字符集不一致会导致汉字变成看不懂的乱码,而且一个汉字字符会变成两个乱码字符。
# 一个汉字变成一个问号
# 一个汉字变成两个问号
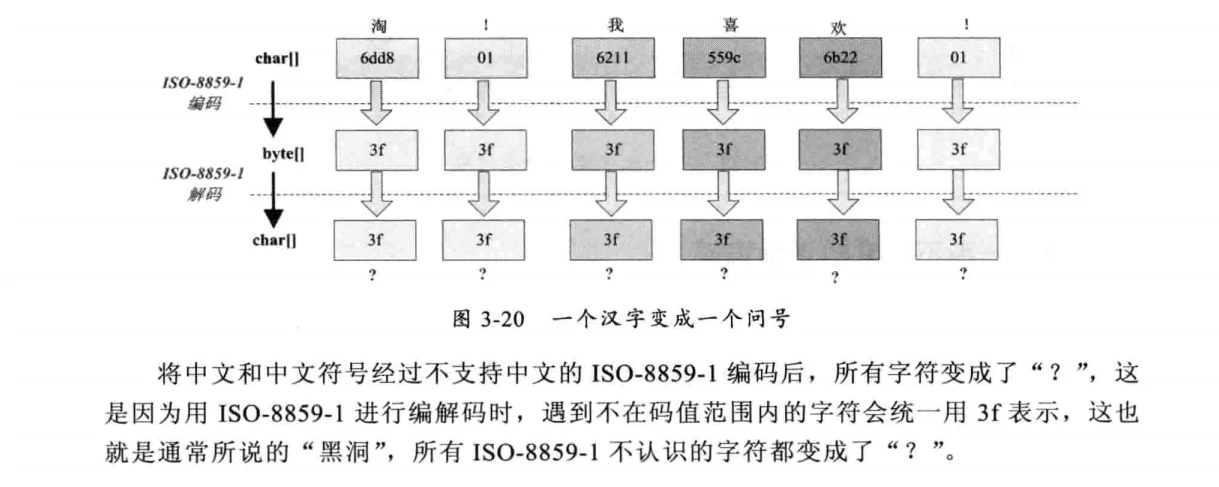
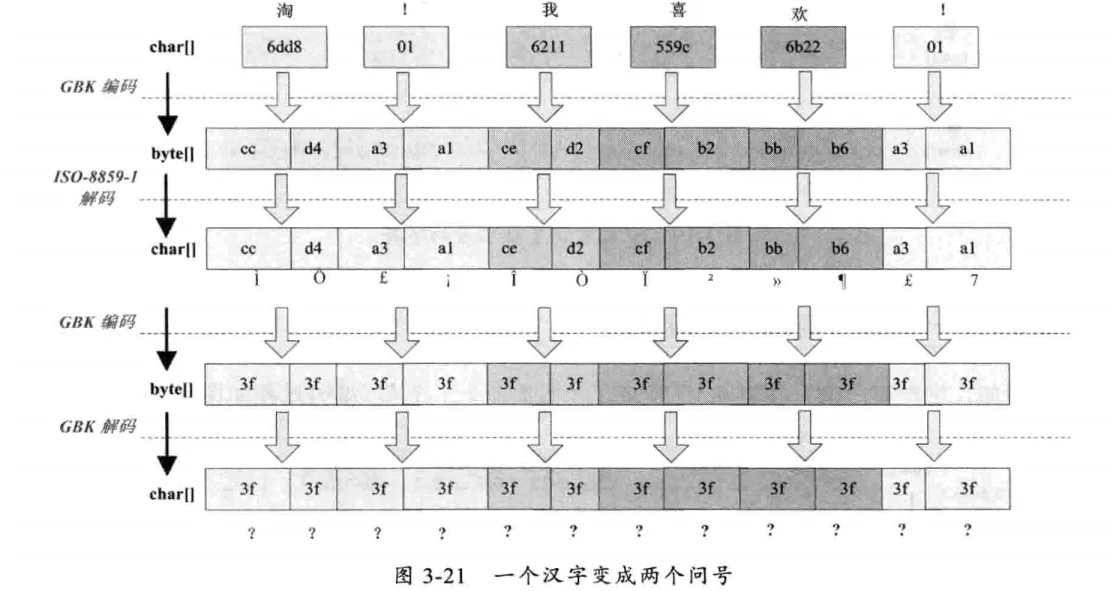
这种情况比较复杂,中文经过了多次编码和解码,其中任何一次编码/解码异常就会出现中文变成?的情况,这时就需要仔细查看中间的编解码环节,找到出现编码错误的地方。
# 一种不正常的正确编码
有一种情况,我们在request.getParameter获取参数时,如果直接使用request.getParameter(name)会出现中文乱码;如果使用String(getParameter(name).getBytes("ISO-8859-1"),"GBK");则可以正常获取中文。这种情况如下图所示:
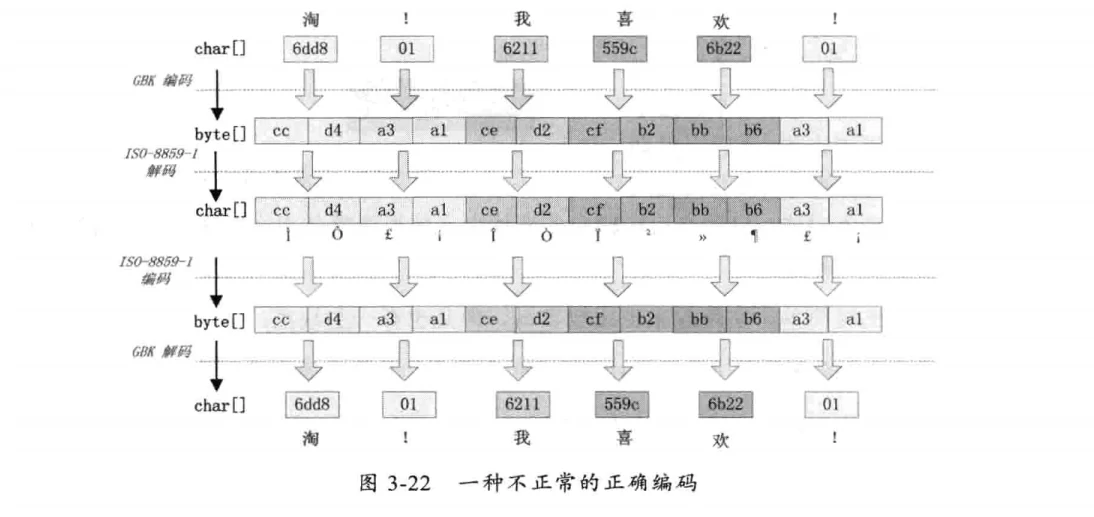
这种情况是这样产生的,ISO-8859-1字符集的编码范围是0000~00FF,正好和一个字节的编码范围对应。这种特性保证了使用ISO-8859-1进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误的“拆分”成两个欧洲字符,但由于输出时也使用了ISO-8859-1,结果被“拆分”的中文字符的两半又被合并到了一起,刚好组成了一个正确的汉字。虽然最终能获取到正确的汉字。但一定不要写这种代码,通过这种方式增加了一次额外的编码与解码。正确的方式应该是在Tomcat的配置文件中将useBodyEncodingForURI设置为“true”,这样tomcat就不会使用默认的ISO-8859-1解析了。
# Javac编译原理
Javac的编译流程主要有词法分析,语法分析,语义分析,字节码生成这4个核心组成部分。
# 词法分析
词法分析器逐个字符读取.java文件,将.java文件转换成Token(标记)流,如下代码:
int a = b + c;
int是由3个字符构成,但是对于词法分析来说,这三个字符会被解析成一个Token(标记)。Token流用于在语法分析过程中生成语法树。
# 语法分析
根据Token集合生成抽象语法树,语法树是一种用来表示程序代码语法结构的表现形式,语法树的每一个节点都代表着程序代码中的一个语法结构,例如包、类型、修饰符。语法分析主要有com.sun.tools.javac.parser.Parser类来实现。
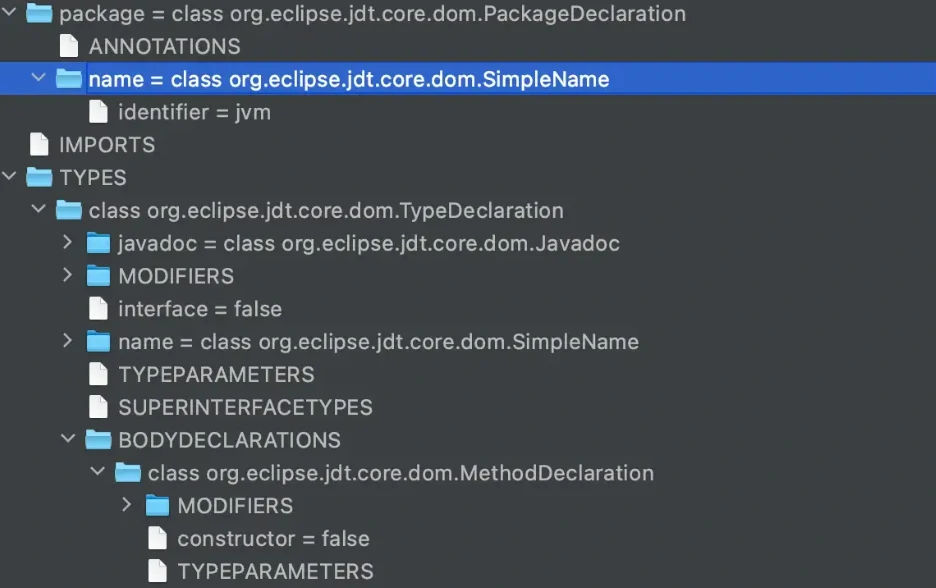
package jvm;
/**
* @author sh
*/
public class ClassTest {
public int add(int a, int b) {
return a + b;
}
}
上述这段代码生成的抽象语法树如下(IDEA JDT AstView插件可以查看抽象语法树):
# 语义分析
语法分析器将Token流解析成更加结构化的,可操作的一颗语法树,但是这颗语法树太枯燥了,离我们的目标Java字节码的产生还有很大的距离。我们必须要在这颗语法树的基础上再做一些处理,如给类添加默认的构造函数,检查变量在使用前是否已经初始化,将一些常量进行合并处理,检查操作变量类型是否匹配,检查所有的操作语句是否可达,检查checked exception异常是否已捕获/抛出,解除语法糖,等等。这些操作完成之后,经过处理的语法树就可以用来生成字节码了。
# 字节码生成
经过语义分析器完成后的语法树已经非常完善了,接下来Javac会调用com.sun.tools.javac.jvm.Gen类遍历语法树,生成最终的Java字节码。
生成Java字节码需要如下两个步骤:
1.将Java方法中的代码块转化成符合JVM语法的命令形式,JVM的操作都是基于栈的,所有的操作都必须经过出栈和入栈来完成。
2.按照JVM文件的组织格式将字节码输出到以.class为扩展名的文件中。